Python and Threading
All modern CPUs have more than one thread. Multi-threading has even reached the embedded world with boards like the ESP32 and the Raspberry Pi Pico. Because of this it only makes sense to write modern code in a way that it can take advantage of this.
Python is one of the most popular programming languages among almost all people who have to write code. It is used for everything from webservers, desktop apps to embedded programs. Among the engineering and scientific community python is turning into the default language. Even Matlab recognizes that python does what it does just better and includes a python editor starting with the 2024.1 release.
Given those two things one would assume that python has some intuitive and easy ways to achieve multi-threading. I mean that is the whole selling point of the language. Ease of use and abstracted complexity. So let’s look how multi threading is commonly done in python.
Before we start let me give a small disclaimer: Don’t use this post as a threading tutorial if you don’t know anything about the general multi-threading pitfalls (deadlocks, data races, …). I will only go over the python multi-threading situation and not about threading design patterns in general.
import threading
Most tutorials and searches will point you to the threading module from the python standard library. In this post I will use a recursive fibonacci series as a threaded compute load. That load runs on all specified threads at the same time.
import threading
import sys
def recursive_fib(n):
if n < 2:
return 1
n1 = recursive_fib(n-1)
n2 = recursive_fib(n-2)
return n1 + n2
fib_depth = int(sys.argv[1])
thread_count = int(sys.argv[2])
thread_list = []
for r in range(thread_count):
new_thread = threading.Thread(target=recursive_fib, args=(fib_depth, ))
new_thread.start()
thread_list.append(new_thread)
for thread in thread_list:
thread.join()
This python example works perfectly fine. To have a baseline to compare the performance to, I also implemented the same code in C++:
#include <iostream>
#include <future>
#include <vector>
uint64_t recursive_fib(uint64_t n){
if (n < 2){
return 1;
}
auto n1 = recursive_fib(n-1);
auto n2 = recursive_fib(n-2);
return n1 + n2;
}
int main(int argc, char* argv[]){
auto fib_depth = std::stoi(argv[1]);
size_t thread_count = std::stoi(argv[2]);
std::vector<std::future<uint64_t>> thread_list{};
thread_list.reserve(thread_count);
for (size_t i = 0; i < thread_count; i++){
auto new_thread = std::async(std::launch::async, &recursive_fib, fib_depth);
thread_list.emplace_back(std::move(new_thread));
}
for (auto& thread:thread_list){
if (thread.valid()){
thread.wait();
}
}
}
For reference I use clang++ 18 with no extra options to compile the code. The system I test on has an amd ryzen 1600x (6 cores 12 threads) and I am using kubuntu 24.04 (beta) as OS. To measure the time I use the time command. I will not testing with the full 12 threads since that would require all of my CPUs threads and the performance would vary greatly depending on the other stuff running on my system. I have about 20 firefox tabs open, music playing and more. Just switching the songs would impact the benchmark.
Besides the explicit types that are required in C++, the code looks basically identical. Both take the fibonacci depth and the amount of threads as a cli argument.
However the main difference is the time the code takes to execute.
Using 1 thread and a depth of 35 the python code takes 1.75 seconds while the C++ code finishes after 0.076 seconds. Since this post is about multi-threading, the 20x speed difference is out baseline. We will assume that the speed in python vs C++ should always scale by a factor of 20. This will be important once we look at how the code scales with more threads.
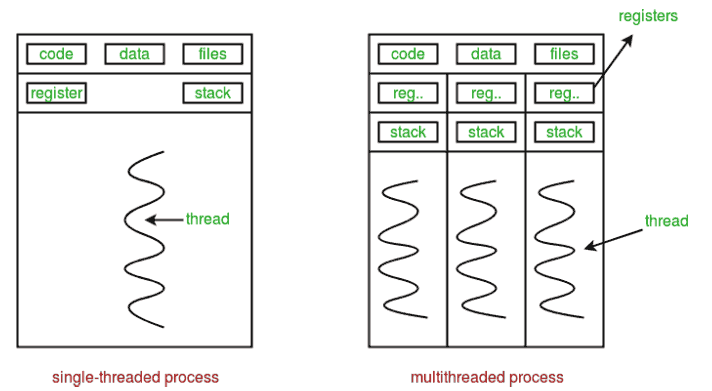
Using 6 threads with the same depth the C++ code takes 0.081 seconds. However using 6 threads the python code suddenly needs 10.91 seconds. That is more than 6 times slower than using one thread and not like you might expect (and like it is in C++) only slightly slower.
Let’s dive into why this is the case.
Python and the GIL
Most python interpreters use a global interpreter lock. Simply said they make sure that in the context of a single interpreter only one part of the python (byte) code is being interpreted at once.
This means the threads of our previous example are not executed at the same time but rather in series. This explains the 6x increase in time needed for 6x the work (albeit on different threads).
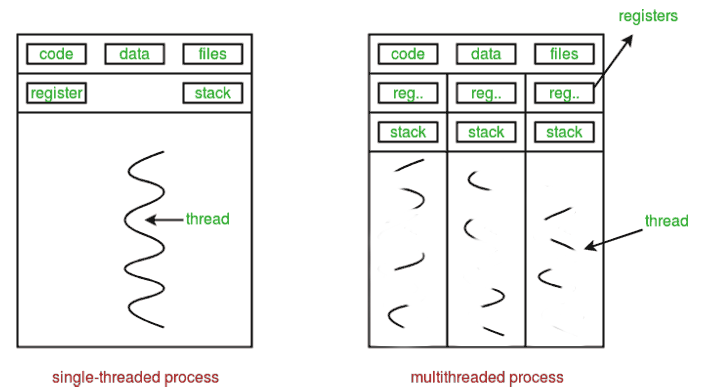
Because of this the use of threading.Thread is only recommended for io heavy concurrency or when interfacing with external libraries (system calls, c libraries,…). The interpreter can run other parts while the external function is running and pending for the result. After all no new code is being interpreted during a system call. The return values can be bound to local temporary variables that get assigned to the actual ones, as soon as the thread is active again.
multiprocessing is the new threading
The python developers are aware if this and naturally have a solution in the standard library: multiprocessing
That package provides the Process class as an alternative to the Thread class. However instead of having multiple threads on the same interpreter these simply launch with a new interpreter per Process. Each Process now has their own GIL. This is almost the same as executing `python myscript.py` in different shells or from the same shell but with the fork command.
import multiprocessing
import sys
def recursive_fib(n):
if n < 2:
return 1
n1 = recursive_fib(n-1)
n2 = recursive_fib(n-2)
return n1 + n2
fib_depth = int(sys.argv[1])
thread_count = int(sys.argv[2])
thread_list = []
for r in range(thread_count):
new_thread = multiprocessing.Process(target=recursive_fib, args=(fib_depth, ))
new_thread.start()
thread_list.append(new_thread)
for thread in thread_list:
thread.join()
This code is almost identical to the previous example the only difference is that threading.Thread is replaced by multiprocessing.Process (and the import is switched).
Executing that code with a depth of 35 and 1 thread still takes 1,84 seconds. However when we increase the thread count to 6 the required time only increases to 2,49 seconds. This is a 35% increase in time for 6 times the work. The C++ code had a time increase of 6.5% for this case but it is way better than the 500% increase of the simple python threading.
So in this case switching from fake multi-threading to truly parallel code in python is straightforward. However things get way more complicated when we want to exchange data between the threads.
What about the result?
The previous examples ignored the final return value. For many tasks this is fine but sometimes you want to get values calculated on a different thread.
First we take a look at how we get the return value in the C++ example:
#include <iostream>
#include <future>
#include <vector>
uint64_t recursive_fib(uint64_t n){
if (n < 2){
return 1;
}
auto n1 = recursive_fib(n-1);
auto n2 = recursive_fib(n-2);
return n1 + n2;
}
int main(int argc, char* argv[]){
auto fib_depth = std::stoi(argv[1]);
size_t thread_count = std::stoi(argv[2]);
std::vector<std::future<uint64_t>> thread_list{};
thread_list.reserve(thread_count);
std::vector<uint64_t> results_list{};
results_list.reserve(thread_count);
for (size_t i = 0; i < thread_count; i++){
auto new_thread = std::async(std::launch::async, &recursive_fib, fib_depth);
thread_list.emplace_back(std::move(new_thread));
}
for (auto& thread:thread_list){
if (thread.valid()){
thread.wait();
results_list.emplace_back(thread.get());
}
}
for (auto& res: results_list){
std::cout << res << std::endl;
}
}
This looks barely any different than before. We just get the result of the function call. Since C++ creates a new thread for the current process, all the memory is shared and passing values is easy. That being said, nothing is done to prevent data races. Since we only use local vales and pass nothing by reference/pointer this doesn't really matter. If we have a shared variable, it is on us to make sure no problems happen.
Getting a return value in python can't be that hard, right? ... Right?
So to get threading in python to work another Process was started to do the work. As a side effect of this no variables are shared at least not in a way that the child process can write to them. So how do we get results?
Sadly in python neither Process not Thread allow you to retrieve the return value of the function. Asyncio async functions can do it, but they are even less parallel than threads. If we have a return value between 0 and 255 the exit code of the process can be used to pass a result. However this is usually not ideal and the exit code should be used for error checking instead.
A look into the multiprocessing documentation helps. Depending on how you want to interact with the Process(es) different exchange objects have to be used. Basically there are three different ways to exchange data: Queues, Pipes and shared memory.

Queues
Queues are probably the simplest way to exchange data between Processes. Any amount of Processes can put and retrieve data to/from the queue. It works well however the queue has no sense of direction. So if you need bi-directional data transfers you should use something else.
Pipes
Pipes allow for bi-directional communication between the parent process and one child process. Creating one will create a parent and a child connection. When creating a Process just pass the child connection. Data sent on one connection can be received with the other one. Make sure to not share the ends of the pipe with more than one Process each unless you use Locks to make sure not more than one Process is accessing the end of the connection at same time.
Shared memory and Server process
If you want to share access to variables with other Processes you can use shared memory and a memory manager. The multiprocessing module comes with shared memory and memory manager functions for the default python types. If you want to share access to custom classes you need to implement your own memory manager.
Conclusion
Multi-threading in python is a mess due to the overly safe specification to python interpreters. It is even worse because python just ignores the return value of the target function. The usability of both the Thread and Process class would go a long way if you could retrieve the return value like you can the exit code. You can write a wrapper class that sets up a pipe to get the result, but I personally think that this should be part of the standard library (although I don't have time to implement it myself).
If you are aware of these things before starting a project, all these problems can be considered in the architecture. If not you might have to refactor large parts of your code base, to get proper threading working. Always make sure to read the documentation before locking down your design (trust me, these problems could have been prevented by reading the python docs instead of relying on some articles and github copilot).